具身智能
分布式 GPU 集群与原生 NVLink 高速互联架构,可高效承载具身智能的多模态数据融合、环境实时建模、大模型训练与端侧推理,以微秒级同步、毫秒级响应,保障智能体在物理世界中精准交互、流畅动作,一站式 AI 开发环境,简化模型部署流程,加速具身智能在人形机器人、服务机器人、工业智造等场景的产品化落地,让智能体更稳定、更高效地适配真实世界。
方案优势
 EB级弹性存储,统一数据底座
EB级弹性存储,统一数据底座提供统一存储底座,实现海量数据集中管理,依托智能分层技术有效降低存储成本,高效打通异构数据孤岛,提升数据管理效率。
 高性能数据处理
高性能数据处理打造高吞吐、低时延的数据处理体系,突破计算资源瓶颈,有效提升大规模模型训练与推理的整体效率。
 智能元数据管理与检索
智能元数据管理与检索智星云智算可对异构数据进行自动关联分析,大幅提升文件检索效率,为仿真决策提供高一致性的训练样本。
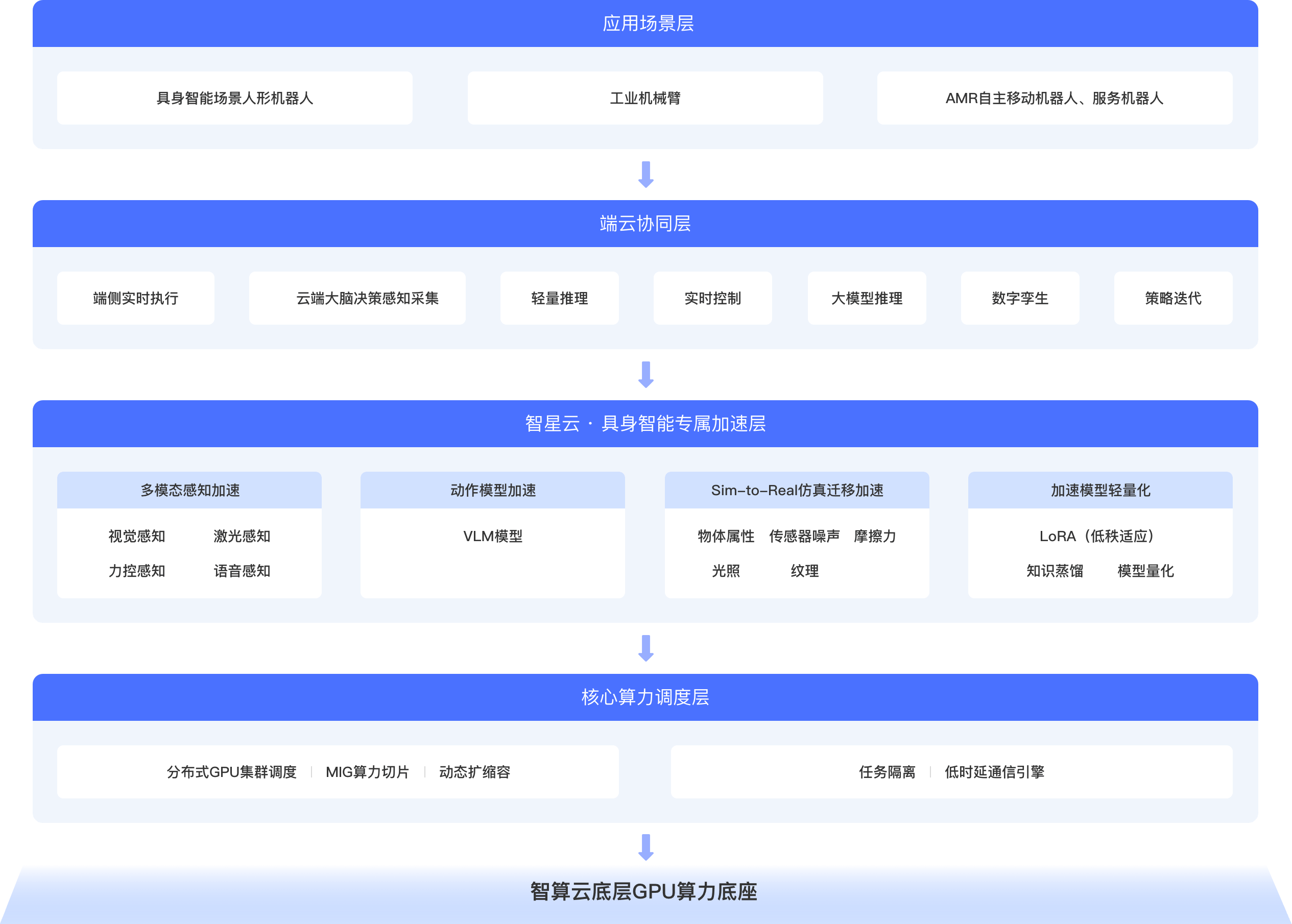
方案架构

搭载 H100/A100/A800/V100 及国产高性能 GPU,支持单卡/多卡/千卡并行。 高速互联:原生NVLink/Switch、InfiniBand HDR,GPU 间通信带宽最大化。 分布式存储:高吞吐并行存储,支撑多模态传感器数据读写。 边缘算力节点:就近部署低时延 GPU节点,缩短端云交互链路。

基于K8s+容器化,支持任务优先级、算力隔离、动态扩缩容。 MIG 算力切片:单卡多实例拆分,适配轻量级推理与调试任务。 跨区域算力调度:支持多可用区冗余,保障业务高可用。

CUDA/TensorRT 优化视觉、激光雷达、力觉、语音等数据处理。 VLA/ViLLA模型加速:视觉-语言-动作大模型训练与推理全栈加速。 仿真到现实(Sim-to-Real)加速:数字孪生环境并行仿真,提升模型迁移效率。 模型轻量化:支持 LoRA/QLoRA 微调、模型蒸馏,适配端侧部署。

预装 PyTorch、TensorFlow、ROS、Isaac Sim 等框架。 模型管理平台:模型训练、版本管理、一键部署、监控告警。 端云协同SDK:提供标准API,快速对接机器人控制器与传感器。 数据处理工具:多模态数据标注、清洗、增强与闭环迭代。
技术架构
应用场景

依托多模态感知与大模型决策,打造通用智能中枢,实现自主交互与复杂动作执行。

融合视觉与力控算法,实现高精度、高柔顺操控,满足工业自动化柔性生产需求。

支持多传感器融合导航与智能避障,实现安全高效自主移动与人机协同作业。

融合视听语义理解,精准响应场景需求,提供自然流畅的多场景智能服务。






